This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
New research evaluating the effectiveness of reward modeling during Reinforcement Learning from Human Feedback (RLHF): “ SEAL: Systematic Error Analysis for Value ALignment.” The paper introduces quantitative metrics for evaluating the effectiveness of modeling and aligning human values: Abstract : Reinforcement Learning from Human Feedback (RLHF) aims to align language models (LMs) with human values by training reward models (RMs) on binary preferences and using these RMs to fine-tu
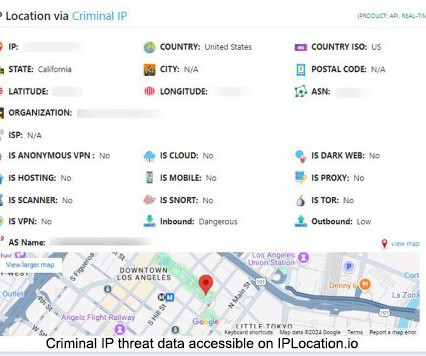
Torrance, Calif., Sept. 11, 2024, CyberNewsWire — Criminal IP , a distinguished leader in Cyber Threat Intelligence (CTI) search engine developed by AI SPERA, announced that it has successfully integrated its IP address-related risk detection data with IPLocation.io, one of the most visited IP analysis and lookup tools on the internet. Through the integration, IPLocation.io , a prominent IP address geolocation tracker platform with a substantial user base, now offers more detailed insights
Adobe addressed tens of vulnerabilities, including critical issues that could allow attackers to execute arbitrary code on Windows and macOS. Adobe Patch Tuesday security updates addressed multiple vulnerabilities in its products, including critical flaws that could allow attackers to execute arbitrary code on Windows and macOS systems. The most severe vulnerabilities are two critical memory corruption flaws in Acrobat and PDF Reader, tracked as CVE-2024-41869 (CVSS score of 7.8) and CVE-2024-45
Many cybersecurity awareness platforms offer massive content libraries, yet they fail to enhance employees’ cyber resilience. Without structured, engaging, and personalized training, employees struggle to retain and apply key cybersecurity principles. Phished.io explains why organizations should focus on interactive, scenario-based learning rather than overwhelming employees with excessive content.
Cybersecurity researchers have uncovered a new set of malicious Python packages that target software developers under the guise of coding assessments. "The new samples were tracked to GitHub projects that have been linked to previous, targeted attacks in which developers are lured using fake job interviews," ReversingLabs researcher Karlo Zanki said.
Researchers observed the RansomHub ransomware group using the TDSSKiller tool to disable endpoint detection and response (EDR) systems. The RansomHub ransomware gang is using the TDSSKiller tool to disable endpoint detection and response (EDR) systems, Malwarebytes ThreatDown Managed Detection and Response (MDR) team observed. TDSSKiller a legitimate tool developed by the cybersecurity firm Kaspersky to remove rootkits, the software could also disable EDR solutions through a command line script
The operators of the mysterious Quad7 botnet are actively evolving by compromising several brands of SOHO routers and VPN appliances by leveraging a combination of both known and unknown security flaws. Targets include devices from TP-LINK, Zyxel, Asus, Axentra, D-Link, and NETGEAR, according to a new report by French cybersecurity company Sekoia.
The operators of the mysterious Quad7 botnet are actively evolving by compromising several brands of SOHO routers and VPN appliances by leveraging a combination of both known and unknown security flaws. Targets include devices from TP-LINK, Zyxel, Asus, Axentra, D-Link, and NETGEAR, according to a new report by French cybersecurity company Sekoia.
SpecterOps has added the ability to track attack paths across instances of Microsoft Azure Directory (AD) running in both on-premises and on the Microsoft Azure cloud service. The post SpecterOps Extends Reach of BloodHound Tool for Mapping Microsoft AD Attacks appeared first on Security Boulevard.
WordPress.org has announced a new account security measure that will require accounts with capabilities to update plugins and themes to activate two-factor authentication (2FA) mandatorily. The enforcement is expected to come into effect starting October 1, 2024.
Week B: Bugs begone! This month Redmond fixes 79 security flaws in Windows and other products The post Microsoft Fixes Four 0-Days — One Exploited for SIX YEARS appeared first on Security Boulevard.
The Singapore Police Force (SPF) has announced the arrest of five Chinese nationals and one Singaporean man for their alleged involvement in illicit cyber activities in the country. The development comes after a group of about 160 law enforcement officials conducted a series of raids on September 9, 2024, simultaneously at several locations.
The DHS compliance audit clock is ticking on Zero Trust. Government agencies can no longer ignore or delay their Zero Trust initiatives. During this virtual panel discussion—featuring Kelly Fuller Gordon, Founder and CEO of RisX, Chris Wild, Zero Trust subject matter expert at Zermount, Inc., and Principal of Cybersecurity Practice at Eliassen Group, Trey Gannon—you’ll gain a detailed understanding of the Federal Zero Trust mandate, its requirements, milestones, and deadlines.
Ivanti fixed a maximum severity flaw in its Endpoint Management software (EPM) that can let attackers achieve remote code execution on the core server Ivanti Endpoint Management (EPM) software is a comprehensive solution designed to help organizations manage and secure their endpoint devices across various platforms, including Windows, macOS, Chrome OS, and IoT systems.
A "simplified Chinese-speaking actor" has been linked to a new campaign that has targeted multiple countries in Asia and Europe with the end goal of performing search engine optimization (SEO) rank manipulation. The black hat SEO cluster has been codenamed DragonRank by Cisco Talos, with victimology footprint scattered across Thailand, India, Korea, Belgium, the Netherlands, and China.
Microsoft Patch Tuesday security updates for September 2024 addressed 79 flaws, including four actively exploited zero-day flaws. Microsoft Patch Tuesday security updates for September 2024 addressed 79 vulnerabilities in Windows and Windows Components; Office and Office Components; Azure; Dynamics Business Central; SQL Server; Windows Hyper-V; Mark of the Web (MOTW); and the Remote Desktop Licensing Service.
Once SBOM and IAM provisioning knit seamlessly with policy-driven data encryption and AI-powered monitoring, they will have a far stronger security posture. The post The SBOM Survival Guide: Why SBOM Compliance is Set to Ignite IoT Security appeared first on Security Boulevard.
Keeper Security is transforming cybersecurity for people and organizations around the world. Keeper’s affordable and easy-to-use solutions are built on a foundation of zero-trust and zero-knowledge security to protect every user on every device. Our next-generation privileged access management solution deploys in minutes and seamlessly integrates with any tech stack to prevent breaches, reduce help desk costs and ensure compliance.
Highline Public Schools, a school district in Washington state, remains closed following a cyberattack that occurred two days ago. Two days ago Highline Public Schools (HPS), a school district in Washington state, suffered a cyber attack that caused a significant disruption of its activities. Highline Public Schools (HPS) is a public school district in King County, headquartered in Burien, Washington, it serves more than 18,000 students.
In this blog entry, we provide an analysis of the recent remote code execution attacks related to Progress Software’s WhatsUp Gold that possibly abused the vulnerabilities CVE-2024-6670 and CVE-2024-6671.
Choosing the right identity provider is crucial, as it requires architectural changes that can make switching later difficult and costly. The post 6 Questions to Answer Before Choosing an Identity Provider appeared first on Security Boulevard.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Imagine a world where you never have to remember another password. Seems like a dream come true for both end users and IT teams, right? But as the old saying goes, "If it sounds too good to be true, it probably is." If your organization is like many, you may be contemplating a move to passwordless authentication.
A critical SQL injection vulnerability has been discovered in LearnPress, a popular WordPress plugin used to create and manage online courses. The flaw, tracked as CVE-2024-8522, carries a maximum CVSS... The post CVE-2024-8522 (CVSS 10): LearnPress SQLi Flaw Leaves 90K+ WordPress Sites at Risk appeared first on Cybersecurity News.
Ivanti fixed a maximum severity flaw in its Endpoint Management software (EPM) that can let attackers achieve remote code execution on the core server Ivanti Endpoint Management (EPM) software is a comprehensive solution designed to help organizations manage and secure their endpoint devices across various platforms, including Windows, macOS, Chrome OS, and IoT systems.
In recent months, the National Public Data (NPD) breach has been a topic of intense scrutiny, with cybersecurity experts like Brian Krebs highlighting the poor security practices that contributed to the breach’s magnitude. As we continue to analyze the aftermath, new findings have come to light that underscore the dangers posed by inadequate security measures … The post New Findings on the National Public Data Breach: Poor Security Measures and the Role of Infostealer Malware as a Possible Vecto
After a year of sporadic hiring and uncertain investment areas, tech leaders are scrambling to figure out what’s next. This whitepaper reveals how tech leaders are hiring and investing for the future. Download today to learn more!
In a concerning development for the cybersecurity community, researchers at ReversingLabs have uncovered a new campaign by the notorious North Korean hacking group, Lazarus. This campaign, an evolution of the previously identified "VMConnect" operation, specifically targets developers with fake coding tests, potentially compromising critical infrastructure and sensitive data across various sectors.
In a recent security advisory, GitLab announced the release of critical security patches for its Community Edition (CE) and Enterprise Edition (EE). The patches address several vulnerabilities, including one classified... The post GitLab Issues Critical Security Patch for CVE-2024-6678 (CVSS 9.9), Urges Immediate Update appeared first on Cybersecurity News.
Palo Alto, Calif., Sept.11, 2024, CyberNewsWire — Opus Security , the leader in unified cloud-native remediation, today announced the launch of its Advanced Multi-Layered Prioritization Engine , designed to revolutionize how organizations manage, prioritize and remediate security vulnerabilities. Leveraging AI-driven intelligence, deep contextual data and automated decision-making capabilities, this innovative engine helps organizations prioritize the most critical vulnerabilities, enhanci
A man from New York City has admitted to computer hacking and associated crimes after being caught with a laptop containing hundreds of thousands of stolen payment card details. Read more in my article on the Hot for Security blog.
Cloud Development Environments (CDEs) are changing how software teams work by moving development to the cloud. Our Cloud Development Environment Adoption Report gathers insights from 223 developers and business leaders, uncovering key trends in CDE adoption. With 66% of large organizations already using CDEs, these platforms are quickly becoming essential to modern development practices.
Microsoft’s September 2024 security update addresses a zero-day vulnerability affecting Smart App Control and SmartScreen. This vulnerability, dubbed “LNK stomping” (CVE-2024-38217), has been actively exploited by hackers since at least... The post LNK Stomping (CVE-2024-38217): Microsoft Patches Years-Old Zero-Day Flaw appeared first on Cybersecurity News.
TL;DR The ability to edit Group Policy Object (GPOs) from non-domain joined computers using the native Group Policy editor has been on my list for a long time. This blog post takes a deep dive into what steps were taken to find out why domain joined machines are needed in the first place and what options we had to trick the Group Policy Manager MMC snap-in into believing the computer was domain joined.
Tech leaders today are facing shrinking budgets and investment concerns. This whitepaper provides insights from over 1,000 tech leaders on how to stay secure and attract top cybersecurity talent, all while doing more with less. Download today to learn more!
We organize all of the trending information in your field so you don't have to. Join 28,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content